Изучение чтению языка x86 ассемблера
Перевод статьи - Learning to Read x86 Assembly Language
Автор - Pat Shaughnessy
Источник оригинальной статьи:
http://patshaughnessy.net/2016/11/26/learning-to-read-x86-assembly-language
Написание языка ассемблера - это то, что лучше оставить экспертам. Чтобы написать код, который запускается непосредственно на вашем микропроцессоре, вам необходимо знать, как работает сегментация памяти, каково предназначение каждого регистра, как коды выполняются в реальном и защищенном режимах и многое, многое другое. И, конечно, современные компиляторы, как правило, будут создавать более быстрый и оптимизированный код, чем когда-либо, без каких-либо ошибок.

16-разрядный микропроцессор Intel 8086 1978 года
(источник: RodolfoNeres через Wikimedia Commons )
{kind=link}
С другой стороны, чтение на ассемблере не так сложно и может оказаться полезным: когда-нибудь вам может понадобиться отладить код без исходного кода. Вы начнете понимать, что может и чего не может сделать микропроцессор, непосредственно читая его язык. И вы еще больше оцените и поймете свой любимый язык программирования, увидев свой собственный код, переведенный в низкоуровневые машинные инструкции.
Но самое главное, изучение ассемблера может быть очень увлекательным.
Обычно чтение на языка ассемблере совсем не весело
К сожалению, большинство из нас видит ассемблер только после того, как что-то пошло не так, ужасно неправильно, когда мы сталкиваемся с чем-то вроде этого:
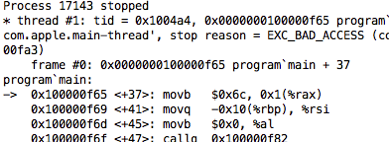
Вот как выглядит ошибка сегментации в отладчике. Отладчик показывает мне язык ассемблера, потому что он не знает, что еще показать мне. «Ошибка сегментации» означает, что одна из инструкций языка ассемблера, например строка movb $ 0x6c, 0x1 (% rax) выше, пыталась записать в часть памяти, которая ему не разрешена.
Неудивительно, что большинству из нас не нравится читать код низкого уровня, подобный этому. Мы видим это только тогда, когда мы находимся в процессе отладки, когда язык и инструменты, на которые мы обычно полагаемся, подвели нас. Мы никогда не видим язык ассемблера при более счастливых обстоятельствах; это всегда носитель плохих новостей.
Преобразование моего собственного кода в язык ассемблера
На этой неделе у меня было немного свободного времени, и я решил просто почитать язык ассемблера. Я хотел прочитать код низкого уровня, который работал правильно, а не код, который перезаписывал память какого-то другого процесса. Я хотел посмотреть, смогу ли я понять это, как любой другой язык программирования. Чтобы упростить задачу, я решил перевести часть своего собственного кода на язык ассемблера, чтобы сосредоточиться на синтаксисе языка ассемблера. Проще было понять, что означают инструкции, потому что я знал, что они делают.
Я разработчик Ruby, поэтому мне было интересно узнать, как мой код на Ruby будет выглядеть переведенным на ассемблер. К сожалению, интерпретатор Ruby (по крайней мере, стандартная версия Ruby «MRI») никогда не делает этого. Вместо этого сам интерпретатор Ruby компилируется в машинный язык и выполняет мой код на виртуальной машине. Но я хотел посмотреть, что будет делать реальная машина, а не виртуальная.
Вместо этого я решил использовать Crystal, разновидность Ruby, которая использует LLVM для компиляции Ruby на родном машинном языке перед его запуском. И поскольку система LLVM может также создавать версию кода на ассемблере, которую она производит, использование Crystal было для меня идеальным способом увидеть мой код Ruby переведенным, чтобы микропроцессор мог его понять.
Я начал с написания чрезвычайно простой программы, которая добавляет 42 к заданному целому числу:
def add_forty_two(n) n+42 end puts add_forty_two(10)
Это был оба кода Ruby:
$ ruby add_forty_two.rb 52
И Кристалл код:
$ crystal add_forty_two.rb 52
Оба, конечно, дали один и тот же результат. Но только Crystal может сделать копию на ассемблере:
$ crystal build add_forty_two.rb --emit asm
Это создало файл с именем add_forty_two.s, который содержал 10000 строк кода ассемблера. (В основном это была скомпилированная версия библиотеки времени выполнения Crystal.) Я открыл add_forty_two.s в текстовом редакторе и искал «add_forty_two», название моей функции. Сначала я нашел сайт вызова, код, который вызывает мою функцию add_forty_two:

Я вернусь к этому чуть позже. Поиск снова, я нашел версию моей функции на ассемблере x86:
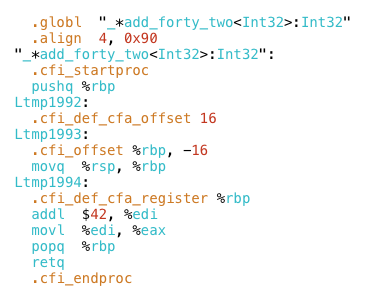
Затем я удалил все директивы ассемблера, такие как .globl и .cfi_offset. Когда-нибудь было бы интересно узнать об этом, но я хотел сосредоточиться на реальных машинных инструкциях. И, наконец, я вставил оставшийся код в мою функцию Ruby.
Затем я увидел, что на самом деле делает мой компьютер, когда он выполняет add_forty_two :

Язык ассемблера x86: почти легко читается
Этот код почти легко следовать. Я могу догадаться, что означает каждая инструкция: нажать, добавить, переместить и т. Д., Но я не совсем понимаю, что здесь происходит. mov, вероятно, означает перемещение, но что движет компьютер? И откуда куда?

Был ли ассемблер x86 разработан в Венгрии?
Проблема в том, что язык ассемблера x86 был разработан венграми. Я не имею в виду это буквально; На самом деле, я понятия не имею, кто разработал язык ассемблера x86. Я имею в виду, что код x86 напоминает мне венгерский язык.
Я жил в Будапеште около года в 1992 году и сумел заговорить по-венгерски, хотя с тех пор я все это забыл. Прекрасный язык, венгерский, как известно, иностранцам трудно выучить. Относящийся только к финскому и эстонскому языкам, его грамматика не похожа на итальянский, французский или другие романские языки; и не похож на русский или любой другой славянский язык из Восточной Европы.
Единственный фрагмент венгерской грамматики, который я до сих пор помню, состоит в том, что вместо использования отдельных слов для предлогов, таких как внутренняя, внешняя и т. Д., Вы добавляете различные суффиксы к целевому слову. Например, «внутри дома» будет хазбан . Дом есть, а внутри - запрет . Точно так же «в Будапеште» будет Будапешт - суффикс en означает «в». Код на языке ассемблера x86 напоминает мне венгерский. Вы не используете mov для перемещения чего-либо; вы используете movq . Вы ничего не добавляете ; Вы используете инструкцию addl .
Оказывается, сборка x86 намного проще, чем венгерская; Есть только несколько простых суффиксов, которые относятся к размеру данных, с которыми вы работаете. Вот два примера:

Инструкция addl действительно означает «добавить длинный», где «длинный» относится к 4-байтовому или 32-битному значению. В Crystal это соответствует типу Int32 , который является целочисленным типом по умолчанию и типом, который использует мой метод add_forty_two .
Вот еще один пример:

Буква q относится к слову «quad» или к 8-битному или 64-битному значению. Большая часть кода x86 в наши дни работает с 64-битными или 32-битными значениями, поэтому вы чаще всего будете видеть инструкции, заканчивающиеся на q или l . Другими суффиксами являются w для слова (16 бит или 2 байта) или b для 1 байта или 8 бит.
x86 Регистры
Но как насчет всех операндов в инструкциях? Почему у всех них есть префикс "%", такой как % rsp или % edi ? Чтение языка ассемблера x86 также напоминает мне чтение кода Perl. Много знаков препинания без видимой причины. Как и в Perl, язык ассемблера x86 использует символы или магические знаки пунктуации для указания типа каждого значения операнда.
Вот мои два примера инструкции снова:

Здесь символ «$» означает, что 42 - это буквальное или «немедленное» значение. Как вы можете догадаться, это строка кода, которая добавляет 42 к чему-то. Но к чему это добавляет? Из символа «%» мы видим, что код x86 добавляет 42 к регистру edi .
А что такое регистр? Короче говоря, микропроцессор внутри вашего компьютера использует регистры для хранения значений во время работы вашего кода. Таким образом, инструкция выше добавляет 42 к любому значению, содержащемуся в регистре edi , и сохраняет его обратно в edi .
Вот второй пример снова:

Эта инструкция, movq , ссылается на два регистра: rsp и rbp . Как вы можете догадаться, он перемещает любое значение, найденное в регистре rsp, в регистр rbp .
Сколько регистров там? Как они называются? Давайте посмотрим на них, используя LLDB:
(lldb) register read
General Purpose Registers:
rax = 0x0000000100300268
rbx = 0x0000000000000000
rcx = 0x00007fffd8132201 libsystem_kernel.dylib`__shmsys + 9
rdx = 0x0000000000000000
rdi = 0x000000000000000a
rsi = 0x00007fff5fbff898
rbp = 0x00007fff5fbffa30
rsp = 0x00007fff5fbff908
r8 = 0x0000000100014b60 add`sigfault_handler
r9 = 0x0000000100400000
r10 = 0x0000000000000000
r11 = 0x0000000000000206
r12 = 0x0000000000000000
r13 = 0x0000000000000000
r14 = 0x0000000000000000
r15 = 0x0000000000000000
rip = 0x0000000100013cd0 add`*add_forty_two:Int32
rflags = 0x0000000000000202
cs = 0x000000000000002b
fs = 0x0000000000000000
gs = 0x0000000000000000
Вы можете видеть, что в процессоре Intel моего Mac более 20 регистров, каждый из которых содержит 64-битное или 8-байтовое значение. LLDB показывает значения в шестнадцатеричном формате. Сегодня у меня нет времени, чтобы объяснить, для чего используются все эти регистры, но вот несколько основных моментов:
-
rax , rbx , rcx и rdx - это регистры общего назначения, используемые для хранения промежуточных значений, загруженных из памяти или используемых во время каких-либо вычислений.
-
rsp - указатель стека, который хранит место в памяти в верхней части стека.
-
rbp - это базовый указатель, который хранит в памяти базу текущего кадра стека.
-
rip - указатель инструкции, который хранит в памяти следующую команду для выполнения
-
и rflags содержит ряд флагов, используемых, например, в инструкциях сравнения.
На самом деле в современном микропроцессоре x86 гораздо больше регистров; LLDB показывает только наиболее часто используемые регистры. Для полного объяснения, полное руководство ко всему этому - Руководство разработчика программного обеспечения Intel . К счастью, код ассемблера моей функции использует только несколько регистров. Мне не нужно понимать их всех.
 Регистры, доступные в наборе команд x86
Регистры, доступные в наборе команд x86
(источник: Immae через Wikimedia Commons )
{kind=link}
Но подожди минутку. Почему моя инструкция addl относится к регистру edi ? Этого нет в списке регистров, показанных LLDB. Где происходит эта операция добавления? Какой регистр он использует?
Это снова те венгерские дизайнеры. Оказывается, что ассемблер x86 также украшает имена регистров, чтобы указать их размеры, аналогично тому, что мы видели выше с суффиксами имен команд. Но для имен регистров синтаксис x86 использует префиксы, а не суффиксы. (В программировании на C венгерская запись фактически относится к практике использования префиксов в именах переменных для указания их типа.)
Какая? Это безумие! Зачем любому языку программирования использовать префиксы для указания размера данных в одном месте, а затем использовать суффиксы для указания того же в другом месте? Чтобы понять это, вы должны помнить, что синтаксис ассемблера не был разработан в одночасье. Вместо этого он постепенно развивался в течение многих лет. Первоначально в регистрах использовались простые двухбуквенные имена: ax , bx , cx . DX , SP и IP . Это были регистры оригинального 16-разрядного микропроцессора 8086 1970-х годов. Позже, в 1980-х годах, когда Intel создала 32-битные микропроцессоры, начиная с 80386, они переименовали (или расширили ) регистры ax , bx , cx и т. Д., Чтобы они стали eax , ebx , ecx и т. Д. Затем они были снова переименованы в rax , rbx и т. д. для 64-битных процессоров.
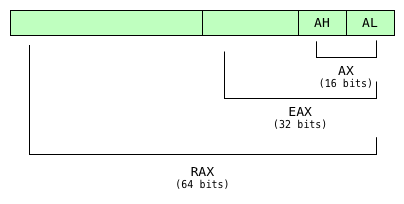
Как вы можете видеть здесь, даже сегодня ассемблерный код x86 может ссылаться на один и тот же регистр, используя много разных имен, например, al или ah для 8-бит, ax бит 16 бит, eax для 32 бит и rax для 64 бит.
Язык сборки x86: читает слева направо, кроме случаев чтения справа налево
Возвращаясь к инструкции по перемещению сверху, как мы узнаем, каким образом происходит перемещение?
То есть эта инструкция перемещает данные из rsp в rbp ? Или из рбп в рсп ? Это читается слева направо или справа налево?
Это может быть либо! Оказывается, есть две версии синтаксиса x86: синтаксис «AT & T или GNU Assembler (GAS)», который я использовал до сих пор, а также синтаксис «Intel». ГАЗ читает слева направо:
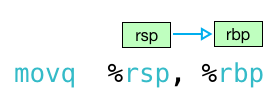
AT & T / GAS синтаксис
Но одинаково верным и распространенным является синтаксис Intel, который читается справа налево:
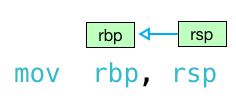
Синтаксис Intel
Если вы видите Perl-подобные сигилы (например, % rsp и % rbp ), то вы читаете синтаксис GAS и значения будут перемещаться слева направо. Если вы не видите никаких знаков «%» или «$», значит, у вас есть синтаксис Intel, а значения перемещаются справа налево. Также обратите внимание, что синтаксис Intel не добавляет «q» или «l» к именам команд. Эта статья делает большую работу, объясняя различия между этими двумя стилями.
Что за крушение поезда! Трудно представить себе более запутанное положение дел. Но опять же, помните, все это развивалось в течение 40 лет. Он не был разработан ни одним человеком в любое время. За каждой инструкцией на языке ассемблера x86 стоит огромная история.
Выполнение моей простой программы
Теперь, когда я понимаю основы синтаксиса языка ассемблера x86, я готов вернуться к своему коду add_forty_two и попытаться понять, как он работает. Здесь это снова:
Читая 6 инструкций внутри add_forty_two , выполняются три разные операции. Сначала мы устанавливаем новый фрейм стека для нашей функции:

Фрейм стека - это область памяти, которую мой код может использовать для сохранения локальной переменной и другой информации. Я не буду тратить время на это сегодня, потому что мой код настолько прост, что не использует никаких локальных переменных. Последние две инструкции очищают этот кадр стека и возвращаются к вызывающему коду:

Я не буду освещать это сегодня. В моей следующей статье я рассмотрю немного более сложный пример, содержащий локальные переменные, и объясню, как код сборки x86 обращается к ним в стеке.
На сегодня я хочу сосредоточиться на двух инструкциях в середине, которые фактически реализуют add_forty_two :

Мы дошли до двух инструкций на ассемблере, но все еще далеко не очевидно, что означает этот код! Ключом к пониманию этих двух инструкций является понимание того, что аргумент моей функции n передается с использованием регистра:

Мы можем убедиться в этом, вернувшись к сайту вызова в файле add_forty_two.s , к коду, который вызывает мою функцию:
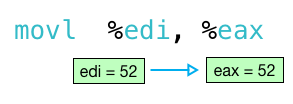
Обратите внимание, как первая команда movl копирует значение 10 в регистр edi (младшие 32 бита регистра rdi ):
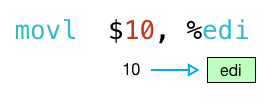
Далее инструкция callq вызывает мою функцию с 10 в edi :
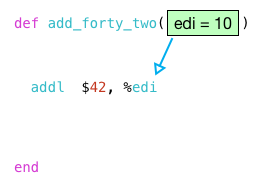
Поэтому, когда инструкция addl выполняется, она добавляет 42 к аргументу 10.
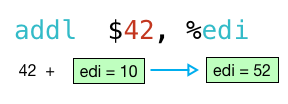
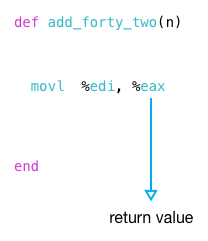
Затем выполняется инструкция movl и копирует результат 52 из edi в eax :
Это, в свою очередь, становится возвращаемым значением из моей функции:
Опять же, мы можем убедиться в этом, снова прочитав код сайта вызова:
Что происходит после возвращения add_forty_two ? Он перемещает % eax , возвращаемое значение, в % edi, где он становится аргументом для второго вызова функции, вызова put .
Я не уверен, является ли этот шаблон использования регистров % edi и % eax для хранения аргументов функции и возвращаемых значений стандартным соглашением x86. Я предполагаю, что вместо этого это шаблон, который использует генератор кода LLVM. Может случиться так, что LLVM использует эту технику только для одного аргумента и функции единственного возвращаемого значения, например add_forty_two .
В следующий раз
Я мало что сделал, но уже начинаю понимать язык ассемблера x86. Почти неразборчиво, когда я впервые увидел это, теперь я могу начать следить за тем, что делают машинные инструкции при выполнении моего кода. Ключ был в том, чтобы узнать, как меняются инструкции и имена регистров в зависимости от размера значения, с которым они работают.
Конечно, есть чему поучиться. В следующей статье я расскажу о том, как микропроцессор x86 использует стек для сохранения значений, и как это сопоставляется с Ruby, используя чуть более сложный пример. По пути я узнаю о нескольких более важных правилах синтаксиса языка ассемблера x86.